Batch Normalization Explained: Theory, Intuition, and How It Stabilizes Deep Neural Network Training
- Aryan
- Dec 18, 2025
- 6 min read
What is Batch Normalization ?
Batch Normalization (BN) is a technique used to make the training of deep neural networks faster and more stable. It works by normalizing the activation values of neurons in a layer using the mean and variance of the current mini-batch. This normalization step is typically applied before or after the activation function of each hidden layer.
When we train a neural network, the inputs to the model are usually normalized, but during forward propagation, the outputs of hidden layers also act as inputs for the next layer. These intermediate values are not necessarily normalized, which can make the training slower and unstable.
Batch Normalization fixes this by adjusting the neuron outputs so that, for each mini-batch:
Mean = 0 ,standard deviation = 1
Applying BN to every hidden layer helps the model:
reach convergence in fewer epochs
make backpropagation smoother
improve training stability
In short, by keeping the distribution of hidden layer outputs under control, Batch Normalization helps the network train faster and more reliably.
Why Use Batch Normalization ?
When working with neural networks, it is generally recommended to normalize the input features so that they are on a similar scale. Normalization makes the data mean-centric (mean ≈ 0) with standard deviation ≈ 1, which helps the model train more efficiently.
If we train a network on unnormalized data, the cost function contour becomes stretched unevenly across different directions. In such cases, we cannot use a higher learning rate, and gradient descent struggles to move efficiently toward the global minimum. As a result, training becomes unstable and slow, and the model may fail to reach the optimal solution.
However, when the data is normalized, the cost surface becomes more uniform, making gradient descent updates more stable. This allows the model to:
use a higher learning rate,
converge faster, and
reach the global minimum more reliably.
The same idea applies not only to input data but also to the outputs of neurons in hidden layers. Since each layer’s output becomes the input to the next layer, it makes sense to normalize these activations as well. Batch Normalization ensures that the activations passed to the next layer have a controlled distribution, which helps:
make backpropagation smoother,
improve gradient flow, and
speed up convergence in deep networks.
In short, Batch Normalization stabilizes and accelerates training by normalizing the outputs of each layer, helping gradient descent reach the optimal values faster and more consistently.
Covariate Shift
Covariate shift occurs when the distribution of input features changes between training and testing, even if the relationship between input and output remains the same. In such cases, although we trained the model correctly, the shift in input distribution causes poor performance during inference, and the model may need retraining.
For example, suppose we train a CNN to distinguish between rose and not rose using images of red roses. The model learns well and performs accurately on similar red rose images. However, during testing, if we give it images of roses in different colors—yellow, white, pink, etc.—the underlying relationship is still the same (a rose is a rose), but the feature distribution has changed. Since the model was never trained on such variations, its performance drops. This mismatch in input feature distribution is known as covariate shift.
In short:
Training Input Distribution | Testing Input Distribution | Result |
Only red roses | Roses of many colors | Model accuracy drops due to covariate shift |
Internal Covariate Shift
Internal covariate shift refers to the change in the distribution of activations inside the network during training. In a deep neural network, the output of one layer becomes the input to the next. As training progresses, the weights keep updating, which means the distribution of these internal activations also keeps changing. This makes training unstable, slows convergence, and forces us to use lower learning rates or careful weight initialization.
To understand this, imagine splitting a deep network into two conceptual parts:
The first part receives inputs (e.g., x₁, x₂) and produces some intermediate output.
The second part uses these intermediate activations as its input.
If the distribution of these intermediate outputs keeps shifting due to changing weights, the second part struggles to learn because it keeps receiving data from a moving distribution. This instability is what we call internal covariate shift.
Batch Normalization helps reduce this problem by ensuring that, at every layer, the activations maintain: mean≈0,standard deviation≈1
As a result:
training becomes faster and more stable,
gradient descent progresses more smoothly, and
deeper networks become easier to optimize.
Without Batch Normalization, we may need to compensate by:
lowering the learning rate, and
using more careful weight initialization strategies.
Therefore, Batch Normalization is widely used to reduce internal covariate shift and stabilize deep neural network training.
How Batch Normalization is Done
Important Points Before We Apply Batch Normalization
Batch Normalization is typically used with Mini-Batch Gradient Descent.
It is applied layer by layer. You may use it on one, many, or all layers of the network.
BN normalizes the activations (outputs of neurons), not just the original input data.
Where BN Fits in a Neural Network
For any neuron, forward propagation first computes:
z = w⋅x + b
Then Batch Normalization is applied usually before the activation function g(z):
a = g(BatchNorm(z))
(Some architectures apply BN after activation, but applying it before is more common.)
Step-by-Step Process of Batch Normalization
Assume a mini-batch contains m activation values z₁, z₂,…,zₘ .
Compute Batch Mean

Compute Batch Standard Deviation

Normalize Each Activation

ϵ is a very small number to avoid division by zero.
Scale and Shift (Learnable Parameters)

Where:
Parameter | Purpose | Learnable? |
γ | Scale factor | Yes |
β | Shift factor | Yes |
Default initialization (e.g., in Keras):
γ = 1 , β = 0
Finally, the normalized value is passed into the activation function:

Why Scale and Shift Again?
If we always force activations to have mean 0 and variance 1, the model might become too restricted. The learnable parameters give flexibility:

If the network decides normalization is not helpful for certain features, it can learn values of γ and β that effectively undo normalization.
Thus, Batch Normalization improves training stability without restricting the network’s ability to learn.
Batch Normalization in Deep Networks
BN is treated as a separate normalization layer inserted like:
Linear/Conv → BatchNorm → Activation
During training, four values are maintained per neuron/channel:
Parameter | Learnable? | Description |
γ | Yes | Scaling parameter |
β | Yes | Shifting parameter |
Moving Mean (μ) | No | Used during inference |
Moving Variance (σ²) | No | Used during inference |
Training Update Rule for BN Parameters

(Just like weights and biases, they are updated through backpropagation.)
Summary of the Batch Normalization Workflow
Step | Operation |
1 | Calculate mean and variance of mini-batch |
2 | Normalize activations using them |
3 | Apply learnable scale and shift (γ, β) |
4 | Pass normalized values into activation |
5 | Update γ and β during backpropagation |
Batch Normalization During Test (Inference Phase)
During testing or inference, we do not use the batch-wise mean and variance computed from the current batch. Instead, Batch Normalization uses the Exponential Weighted Moving Average (EWMA) of the mean and variance that were updated during training.
Why not use batch statistics during testing?
Because during inference, the model may receive:
a single sample
a batch with a different distribution
or a different batch size than training
So, to keep predictions stable and consistent, we use the running (moving) estimates accumulated during training.
How the Running Mean & Variance are Stored
During training, Batch Normalization maintains, for every neuron (or channel):
Parameter | Learnable? | Description |
γ (scale) | Yes | Learned during backpropagation |
β (shift) | Yes | Learned during backpropagation |
Moving mean μₑₘₐ | No | Used during testing |
Moving variance σ²ₑₘₐ | No | Used during testing |
So, each BN unit stores 4 parameters:
two learnable (γ, β) and two non-learnable (moving mean and moving variance).
Example:
If a hidden layer has 3 neurons and Batch Normalization is applied, total BN parameters = 3 neurons × 4 values each = 12 parameters
Among them,
6 learnable (γ, β) + 6 non-learnable (moving mean, variance)
What Happens at Test Time ?
The batch normalization formula during inference becomes:
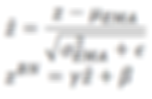
Thus, the model uses stable running statistics instead of batch-level values.
Advantages of Batch Normalization
More Stable Training
Batch Normalization reduces internal covariate shift, allowing the model to train reliably.
It also gives more flexibility when tuning hyperparameters because training becomes less sensitive to initialization and learning rate values.
Faster Convergence
Because BN smooths and stabilizes gradients, we can often use a higher learning rate, leading to faster convergence in fewer epochs.
Acts as a Regularizer (Helps Reduce Overfitting)
BN introduces slight randomness because the mean and variance depend on each mini-batch. This has a regularization-like effect, reducing overfitting.
However, Batch Normalization is not a full replacement for techniques like Dropout—it just provides a mild regularization benefit.
Reduced Dependence on Weight Initialization
Models without BN often require careful weight initialization. With BN, training becomes less sensitive to initial weight values, making network design easier.
Benefit | Effect |
Stable gradients | More reliable and consistent training |
Higher learning rates | Faster convergence |
Mild regularization | Less overfitting |
Easier initialization | Less sensitivity to starting weights |