Perceptron: The Building Block of Neural Networks
- Aryan

- Oct 11, 2025
- 6 min read
What is a Perceptron?
A Perceptron is a fundamental algorithm in supervised machine learning, often compared to others like linear regression, SVM, and logistic regression. It's best understood as a mathematical model or function that serves as the basic building block of deep learning—which is why we study it first.

The diagram above shows its simple design. Let's break down how it works:
Inputs, Weights, and Bias: The model receives inputs, shown as x₁ and x₂. The connections from these inputs to the summation unit have weights (w₁, w₂), which represent the importance of each input. An additional input, the bias (b), is also included.
Weighted Sum: The Perceptron calculates a weighted sum of the inputs. This is done by multiplying each input by its corresponding weight and then adding the bias. The result of this step is 'z'.
z = w₁x₁ + w₂x₂ + b
Activation Function: The value 'z' is then passed to an activation function, denoted by 'f'. The purpose of this function is to convert 'z' into a specific output range, such as 0 to 1 or -1 to 1. Common activation functions include the Step function, ReLU, and Tanh.
In short, the entire process involves taking inputs, applying weights and a bias, and then using an activation function to produce the final output value.
How is the Perceptron Used? A Practical Example
Let's understand this with a real-world scenario. Imagine we have data for 1,000 students. We want to predict whether a student gets placed in a job based on two features: their IQ and their CGPA. The output, 'Placed', is either 1 (Yes) or 0 (No).
IQ | CGPA | Placed |
78 | 7.8 | 1 |
69 | 5.1 | 0 |
.. | .. | .. |
The Perceptron model works in two main stages: training and prediction.
1. The Training Phase
First, we train the model using our student data. In this phase, the model's main goal is to find the ideal values for the weights (w₁, w₂) and the bias (b). It learns by looking at the existing data and adjusting these values to make its predictions as accurate as possible. In our diagram, x₁ would be the student's IQ and x₂ would be their CGPA.
2. The Prediction Phase
Once the model is trained, it's ready to make predictions for new students. Let's assume that after training, our model learned the following values (for demonstration purposes):
Weight for IQ (w₁) = 1
Weight for CGPA (w₂) = 2
Bias (b) = 3
Now, a new student comes along with an IQ of 100 and a CGPA of 5.1. Here’s how the Perceptron predicts the outcome:
It calculates the weighted sum, 'z':
z = (w₁*IQ) + (w₂*CGPA) + b
z = (1*100) + (2 * 5.1) + 3 = 113.2
This 'z' value is then passed to an activation function. If we use a simple step function where any value greater than zero means 'Placed', the model will predict 1 (Placed) for this student.
This design is also scalable. If we had more features, like attendance or project scores, we would simply add more inputs (x₃, x₄, etc.) with corresponding weights to the Perceptron.
Neuron vs. Perceptron: The Biological Inspiration

As the images show, the Perceptron (right) is a simplified mathematical model inspired by the biological neuron (left). We learn in biology that the nervous system is built from billions of these interconnected neuron cells. Let's explore how the two compare.
The Analogy: How are they similar?
The design of the Perceptron directly mimics the basic function of a neuron.
Dendrites → Inputs: A neuron's dendrites receive signals from other cells. Similarly, a Perceptron receives multiple input values (x₁, x₂, etc.).
Cell Body / Nucleus → Summation & Activation: The neuron's cell body processes the incoming signals. In a Perceptron, this processing is done in two steps: calculating the weighted sum and then passing the result to an activation function.
Synapse → Output: A neuron fires an output signal through its synapses to other neurons. The Perceptron's output value is likewise passed on, typically to other Perceptrons in a neural network.
On a larger scale, just as a collection of billions of neurons forms a brain, a collection of Perceptrons forms an artificial neural network.
The Reality: What are the key differences?
Despite being inspired by it, a Perceptron is far simpler than a real neuron.
Complexity: A biological neuron is a complex living cell with intricate internal chemistry. A Perceptron is a simple, well-defined mathematical formula.
Processing: The exact way a neuron processes information in its nucleus is still not fully understood. In a Perceptron, the process is perfectly clear: it's just a sum and an activation.
Plasticity: Biological neurons display neuroplasticity—their connections can strengthen or weaken, new connections can form, and cells can die. This allows the brain to adapt and change over time. While a Perceptron's weights change during training (which is how it "learns"), its basic structure remains fixed. It doesn't create new inputs or connections on its own.
In summary, a Perceptron is a powerful concept borrowed from biology, but it's a very streamlined and simplified version designed for computation.
Interpreting the Model's Weights
So, after training our model on the student data, we get our final values for the weights and bias. But what do these numbers actually tell us?
Let's assume after the training process, our model learned the following values:
Weight for IQ (w₁) = 2
Weight for CGPA (w₂) = 4
Bias (b) = 1
These weights reveal how the model "thinks". They represent the importance of each feature in making the final prediction. A larger weight means the model has learned that the corresponding feature has a stronger influence on the outcome.
In our example, the weight for CGPA (w₂ = 4) is significantly higher than the weight for IQ (w₁ = 2). This gives us a clear insight: the model has determined that a student's CGPA is a much more important factor than their IQ when predicting whether they will be placed.
In essence, the learned weights provide a straightforward way to understand which features the model relies on most, telling us a story about feature importance.
Geometric Intuition: What a Perceptron Actually Sees
Let's get visual and understand what a Perceptron is really doing with our student placement data. We have two inputs—IQ (x₁) and CGPA (x₂)—and our model's job is to predict a 0 (not placed) or a 1 (placed).
The core of the Perceptron is its decision rule: y = 1 if z ≥ 0, and y = 0 if z < 0, where z = w₁x₁ + w₂x₂ + b.
Since we have two features, we can plot every student on a simple 2D graph. Imagine we use a green dot for a placed student and a red dot for a student who wasn't. Our data might look something like this:
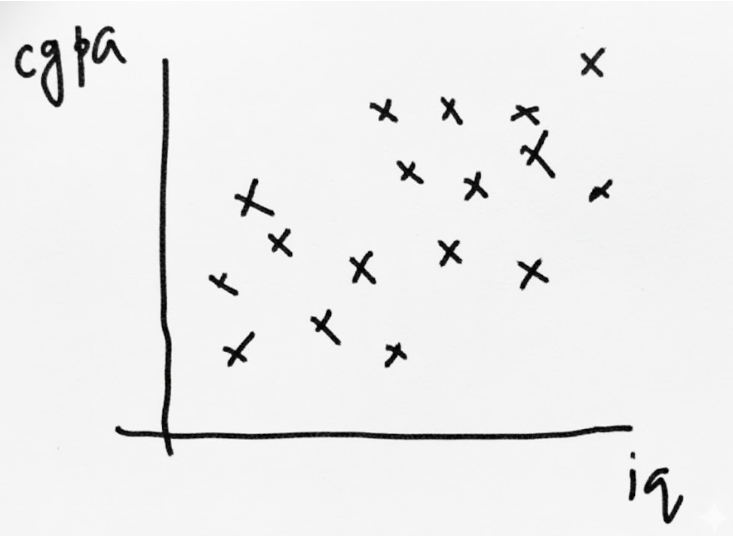
The Dividing Line
Looking at that plot, the goal is to separate the green dots from the red ones. The Perceptron's clever trick is to find a single straight line to do the job.
How does it find this line? The tipping point between predicting a 1 and a 0 is the exact moment when z = 0. This gives us the equation:
w₁x₁ + w₂x₂ + b = 0
If you remember your high school math, that's the equation for a straight line! So, a Perceptron in 2D is nothing more than a line. This line acts as our decision boundary.

Everything on one side of the line will make z positive, so the model classifies it as "placed." Everything on the other side makes z negative and gets classified as "not placed." Because it divides the data into two groups, the Perceptron is a binary classifier.
What About More Features? From Lines to Planes
This is simple enough for two features, but what if we add a third, like "12th-grade marks"? Now our data exists in a 3D space.
In this case, the Perceptron's decision boundary is no longer a line but a flat plane that slices the 3D space in two. For four or more features, we can't visualize it, but the idea is the same. The boundary is called a hyperplane, but its job is always to cut the data into two regions.
The Perceptron's Biggest Limitation
This sounds great, but there’s a huge catch. The Perceptron can only succeed if the data can be perfectly separated by a single straight line (or plane/hyperplane). We call this linearly separable data.
If the dataset is non-linear (for example, overlapping circles or complex curves), the perceptron fails to classify correctly.
Its accuracy drops because no single line or plane can properly split such data.
This is why the Perceptron is limited to being a linear classifier that works best when the data is roughly linear.


