
Regularization
- Aryan

- Feb 7, 2025
- 2 min read
Updated: May 25, 2025
Regularization is a technique used in machine learning and statistics to prevent overfitting, which occurs when a model learns the noise in the training data rather than the underlying patterns. Overfitting can lead to poor generalization to new, unseen data. Regularization introduces additional information or constraints to the model, which helps simplify it and improve its performance on unseen data.
When to use Regularization ?
Prevent Overfitting : Regularization is most commonly used as a tool to prevent overfitting. If your model performs well on the training data but poorly on the validation or test data, it might be overfitting and regularization could help.
High Dimensionality : Regularization is particularly useful when you have a high number of features compared to the number of data points. In such scenarios, models tend to overfit easily, and regularization can help by effectively reducing the complexity of the model.
Multicollinearity : When features are highly correlated (multicollinearity) , it can destabilize your model and make the model's estimates sensitive to minor changes in the model . L2 regularization (Ridge regression) can help in such cases by distributing the coefficient estimates among correlated features.
Feature Selection : If you have a lot of features and you believe many of them might be irrelevant, L1 regularization (Lasso) can help. It tends to produce sparse solutions, driving the coefficients of irrelevant features to zero , thus performing feature selection.
Interpretability : If model interpretability is important and you want a simpler model, regularization can help achieve this by constraining the model's complexity.
Model performance : Even if you're not particularly worried about overfitting, regularization might still improve your model's out-of-sample prediction performance.
Key concepts of Regularization :
Overfitting vs. Underfitting
Overfitting: The model is too complex and captures noise in the training data, leading to high accuracy on training data but poor performance on validation/test data.
Underfitting: The model is too simple to capture the underlying patterns in the data, resulting in poor performance on both training and validation/test data.
Bias-Variance Trade-off
Regularization helps to balance the bias-variance tradeoff:
A model with high bias pays little attention to the training data and oversimplifies the model.
A model with high variance pays too much attention to the training data and captures noise.
Types of Regularization :->
L1 Regularization (Lasso) : L1 regularization adds a penalty equal to the absolute value of the magnitude of coefficients (weights) to the loss function:

L1 regularization can lead to sparse models, where some coefficients become exactly zero, effectively performing feature selection.
L2 Regularization (Ridge) : L2 regularization adds a penalty equal to the square of the magnitude of coefficients to the loss function:
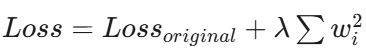
L2 regularization shrinks the coefficients but does not set them to zero, meaning all features are retained but with reduced impact.
Elastic Net Elastic Net combines both L1 and L2 regularization:

This approach is useful when there are multiple correlated features, as it can select groups of correlated features.
Choosing Regularization Strength : The strength of regularization is controlled by a hyperparameter (often denoted as λ or α). A higher value of this parameter increases the amount of regularization applied, which can help reduce overfitting but may also lead to underfitting if set too high.


