
Support Vector Machine (SVM) – Part 1
- Aryan

- Apr 26, 2025
- 10 min read
Maximal Margin Classifier (Support Vector Machine - Hard Margin SVM)
Let’s consider a dataset of 100 students, where we have two input features :
CGPA
IQ
And one output label :
Placement Status (Placed or Not Placed)
We visualize this data in 2D space, where each point represents a student. The green points represent students who are placed, and the red points represent students who are not placed.

This plot shows two classification models, Model 1 and Model 2, each attempting to separate the two classes using a straight line.
Which Model Is Better ?
Although both models correctly classify the training data, Model 2 is better. Here’s why :
Model 1 passes very close to both classes, nearly touching some of the training points.
This proximity increases the risk of misclassification for new or unseen test data.

For example, points like Point 1 (green) and Point 2 (red) near the margin may be misclassified by Model 1.
Model 2, on the other hand, maintains a wider gap (margin) from the nearest points of both classes.
This leads to a more robust model, less sensitive to noise or small data variations.
In SVM terminology, the goal is not just to draw any separating line, but to draw one that maximizes the margin between the two classes.

Let’s define the margin :
If Model 1 has a margin of d1, and Model 2 has a margin of d2, and d2 > d1, then :
Model 2 is the better classifier because it provides greater separation between the classes.
Core Intuition Behind SVM (Hard Margin)
The Support Vector Machine (SVM) follows this core principle :
“Find the hyperplane that maximally separates the two classes with the largest possible margin.”
It's not just about classifying the training data correctly.
SVM strives to be like a “topper” – it aims to maximize performance by increasing the separation between the two classes.
The support vectors (closest points to the margin) define this margin.
A line that maximally separates the classes is less likely to misclassify future data.
Key Takeaways
Many lines may classify the data correctly.
But only one line maximizes the margin — and that’s the one chosen by SVM.
Therefore, SVM is also called a Maximum Margin Classifier .
Basic Requirement for Maximal Margin Classifier (Hard Margin SVM)
The Maximal Margin Classifier or Hard Margin SVM comes with a crucial assumption :
-> The data must be linearly separable.
This means that there must exist a straight line (or hyperplane in higher dimensions) that can perfectly separate the two classes without any misclassification.
If the classes overlap or the data is non-linear, then the hard margin approach will fail.
In such cases, we need to switch to a Soft Margin SVM or use kernel methods to transform the data into a space where it is linearly separable.
So, it is very important to check for linear separability before applying Hard Margin SVM.
Support Vectors and Margins in SVM

In the image above, we see a classification problem involving student data. The green crosses represent students who are placed, and the red crosses represent students who are not placed. Two possible separating lines (Model 1 and Model 2) are shown, each with margins marked by dashed lines.
Let’s focus on an important concept in SVM : support vectors.
In this 2D space, each student (data point) is represented as a vector.
Among all these vectors, some are special — these are the ones that lie exactly on the margin boundaries (the dashed lines).
These special vectors are called support vectors.
Why are support vectors important ?
The margin is defined as the distance between the decision boundary (model line) and the nearest data points from each class — these nearest points are the support vectors.
The entire position and orientation of the optimal hyperplane (model line) depends only on the support vectors, not on other points.
Support vectors are the first points the margin “touches” as it extends out from the decision boundary in both directions.
In essence, the definition and calculation of the margin come directly from the support vectors. This is why the name "Support Vector Machine" — the model “leans” on these vectors to find the optimal boundary.
MATHEMATICAL FORMULATION
We aim to find a line (also known as the hyperplane in higher dimensions) that not only classifies the data correctly but also maximizes the distance between the two margin lines. This distance is known as the margin. Our objective is to find the optimal line such that:
All data points lie on the correct side of the margin.
No data points lie between the margins or cross them.
The margin is as wide as possible.

As illustrated in the diagram, we have a central decision boundary (solid line) and two margin boundaries (dashed lines). This configuration helps the model generalize better by creating the maximum margin classifier.
To model this scenario mathematically :
Since the data is in 2D, the separating line can be represented as a linear equation :
Ax + By + C = 0
When we apply SVM, the algorithm will determine the optimal values of A, B, and C.
The goal is to maximize the margin by adjusting these parameters such that no data points fall inside the margin area.
To formalize the margins :
The central line (decision boundary) is :
Ax + By + C = 0
The positive margin is :
Ax + By + C = 1
The negative margin is :
Ax + By + C = −1
These margins are set at ±1 for mathematical convenience. This simplifies the optimization process and allows us to frame constraints like :

for all data points (xᵢ , yᵢ), where yᵢ is the class label (+1 or -1).
We'll understand why these margins are set at ±1 by referring back to the diagram and exploring the geometric intuition behind it.
Understanding Margin Geometry with Line Equations
Let’s consider a linear equation :
3x + 5y + 9 = 0
This represents our central decision boundary. Now, to define the margin, we construct two parallel lines on either side :
Positive side line: 3x + 5y + 9 = 1
Negative side line: 3x + 5y + 9 = −1
The benefit of using ±1 is that it allows us to define equal margins on both sides of the central line.

Effect of Multiplying the Equation
If we multiply the entire equation by a constant (e.g., 5), it becomes :
15x + 25y + 45 = 0 , 15x + 25y + 45 = ±1
Even though the equation represents the same geometric line, the margins become narrower. This is because the scaling affects the relative distance between the central line and the margins.

Effect of Dividing the Equation
Next, if we divide the original equation by 10 :
0.3x + 0.5y + 0.9 = 0 , 0.3x + 0.5y + 0.9 = ±1
Now the margin becomes wider, because dividing the coefficients increases the perpendicular distance between the boundary and the margin lines.

Why Use +1 and -1 for Margins ?
We standardize the margin boundaries at +1 and -1 because :
It ensures that the distance from the decision boundary is equal in both directions.
It simplifies the constraint during optimization in SVM :

Using any other unequal values like 2 and 3, or 4 and 5, would bias the margin toward one class.
Essentially, using ±1 is a normalization technique that ensures symmetry. What matters most is that the offset from the central line is equal but opposite, i.e., +M and -M. In SVM, we set M=1 to simplify computation.
Our goal in SVM is to find the line Ax + By + C = 0 such that :
The margin (distance between Ax + By + C = 1 and Ax + By + C = −1) is maximized.
No data points fall between or violate the margin boundaries.
SVM Margin Condition Explanation
Let's consider a dataset as shown below :

We have red points (negative class, labeled -1) and green points (positive class, labeled +1).
There are three parallel lines:
A central decision boundary (the model line): 3x + 5y + 9 = 0
A positive margin line: 3x + 5y + 9 = 1
A negative margin line: 3x + 5y + 9 = -1
These lines form the SVM margin region. The red and green points should not cross into the margin region of the opposite class.
Positive vs. Negative Regions of a Line
Every line divides the plane into two regions :
If we plug a point (x, y) into the line equation Ax + By + C :
If the result is > 0, the point lies in the positive region.
If the result is < 0, it lies in the negative region.
If the result is = 0, the point lies exactly on the line.

For example, for the line 3x + 5y + 9 = 0 , green points lie in the positive region of the line, while red points lie in the negative region — which is what we want.
Mathematical Conditions in SVM
In SVM, we want to ensure :
Green points (positive class, label +1) lie on or beyond the positive margin.
Red points (negative class, label -1) lie on or beyond the negative margin.
Let the general line equation be :
Ax + By + C = 0
For green points :
To ensure they do not cross the positive margin, we apply the condition:
Ax + By + C ≥ 1
For red points :
To ensure they do not cross the negative margin, we apply the condition:
Ax + By + C ≤ −1
These can be unified as a single SVM condition :


If this condition is satisfied for all points, it means :
Green points are outside (or on) the positive margin.
Red points are outside (or on) the negative margin.

Each line has a positive and negative region.
Plug a point (x, y) into the line to determine where it lies.
SVM sets margin boundaries using the same coefficients but shifts the constant term.
The constraint yᵢ(Axᵢ + Byᵢ + C) ≥ 1 ensures no point crosses into the margin of the opposite class.
Goal of SVM
We want to find the line (hyperplane) that maximizes the margin (distance d) between the two classes of points — positive (+1) and negative (−1) — while ensuring that:
Positive points lie outside or on the positive margin.
Negative points lie outside or on the negative margin.
This setup is often called the maximum-margin classifier.
Margin Boundary Equations
Let the hyperplane equation be :
Ax + By + C = 0
The positive margin line is :
Ax + By + C = +1
The negative margin line is :
Ax + By + C = −1

SVM Constraint (Unified Form)
Instead of writing two separate inequalities :

We unify the constraints into one equation using labels yᵢ ∈ {+1,−1} :

This clever multiplication handles both conditions in one go.
Optimization Objective (Hard-Margin SVM)

Example
Suppose we have a point (3 , 4) and line coefficients A = 3 , B = 4 , C = 5 :
Compute the expression :
Ax + By + C = 3(3) + 4(4) + 5 = 9 + 16 + 5 = 30
If y = 1 :
y(Ax + By + C) = 1⋅30 = 30 ≥ 1
If y = -1 :
y(Ax + By + C) = −1⋅30 = −30 ≥ 1 (fails, as expected for misclassified point)
final equation :

is exactly the constraint used in Support Vector Machines. When paired with minimizing A² + B² , this forms the full SVM optimization problem.
Understanding the Margin in SVM : How to Compute the Distance d
One key aspect in Support Vector Machine (SVM) formulation is calculating the margin d, which represents the shortest distance between two parallel hyperplanes separating the data.
Geometrical Insight


Application to SVM
In SVM, the margin-defining hyperplanes are :
AX + BY + C = 1 and AX + BY + C = −1
These can be rearranged as :
AX + BY + C − 1 = 0
AX + BY + C + 1 = 0
Thus, the distance between them becomes :

Final Objective (Loss Function)
The SVM optimization objective is to maximize the margin dd. Hence, the loss function becomes :
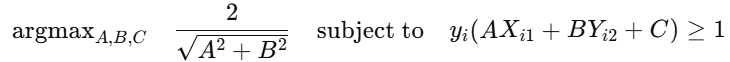
Problems with Hard Margin SVM
Hard Margin SVM assumes that the data is perfectly linearly separable, meaning it tries to find a decision boundary (hyperplane) that completely separates the two classes without any misclassification and with the maximum possible margin.
However, this approach has several limitations :
Sensitive to Misclassifications :
If even a single data point from one class lies on the wrong side of the margin or in the region of the other class, the hard margin approach fails. For example, if one red point appears among green points, or vice versa, the model cannot find a perfect separating hyperplane.
No Tolerance for Outliers :
Hard Margin SVM does not allow any violations of the margin. This makes it highly sensitive to outliers. A single outlier can drastically change the position of the decision boundary or make it impossible to find a solution.
Poor Generalization :
By trying to perfectly separate the training data, Hard Margin SVM can lead to overfitting, especially in real-world data where noise and mislabeled points are common.
Due to these drawbacks, Hard Margin SVM is rarely used in practice. Instead, we use Soft Margin SVM, which allows for some misclassifications and provides better generalization by introducing a trade-off between maximizing the margin and minimizing the classification error.
Prediction in Hard Margin SVM
Once the SVM model is trained, we obtain the parameters of the decision boundary — typically in the form of a linear equation :
ax + by + c = 0
This is the equation of the decision boundary (model line) that separates the two classes.
Key Points:
The margin lines (which are at ax + by + c = +1 and ax + by + c = −1) are only used during training, to maximize the margin and help find the optimal separating hyperplane.
During prediction, only the main model line (the decision boundary) is used to classify new data points.
How to Predict a New Point
Suppose we receive a new data point, for example :
(x , y) = (8 , 80)
To predict the class of this point :
Substitute the values into the model equation :
a(8) + b(80) + c
Interpret the result :
If the result is greater than or equal to 0, the point lies on or above the decision boundary → classified as Positive (e.g., placement will happen).
If the result is less than 0, the point lies below the decision boundary → classified as Negative (e.g., placement will not happen).
This is how SVM makes predictions: by checking which side of the decision boundary the point falls on.


